Test Like You Build: Why Agent Testing Depends on Architecture
Your testing strategy should match your architecture: simple chatbots need input/output tests, deep agents need full trace evaluation.
Test Like You Build: Why Agent Testing Depends on Architecture
Your agent has 10 tools. You test 0 of them behaviorally.
The Testing Gap
After auditing production AI agents at QuantumFabrics, I've found the same gap everywhere. Teams test infrastructure brilliantly:
describe("Error Recovery Middleware", () => {
it("returns true for schema validation errors", () => {
const error = new Error("Received tool input did not match expected schema");
expect(isRecoverableError(error)).toBe(true);
});
});
They track resilience metrics:
const metricsStore = {
emptyMessageDetections: 0,
recoveryAttempts: 0,
recoverySuccesses: 0,
modelRetries: 0,
toolRetries: 0,
};
But who tests the agent's judgment?
What's Missing
1. Policy Compliance Testing
Can your agent be tricked into:
- Emailing external domains?
- Deleting protected files?
- Leaking PII?
- Violating business rules?
Most teams discover these issues in production.
2. Behavioral Snapshots
If you change your prompt:
- Does output quality degrade?
- Do tool calling patterns change?
- Do edge cases break?
Without behavioral snapshots, you're flying blind.
3. A/B Testing
Is Claude 3.5 actually better than Claude 3.0 for your specific task? Without A/B infrastructure, you're guessing.
4. Load Testing
How does your agent behave under concurrent user stress? Non-deterministic systems often degrade in unexpected ways.
The Solution Framework
You need three types of agent testing:
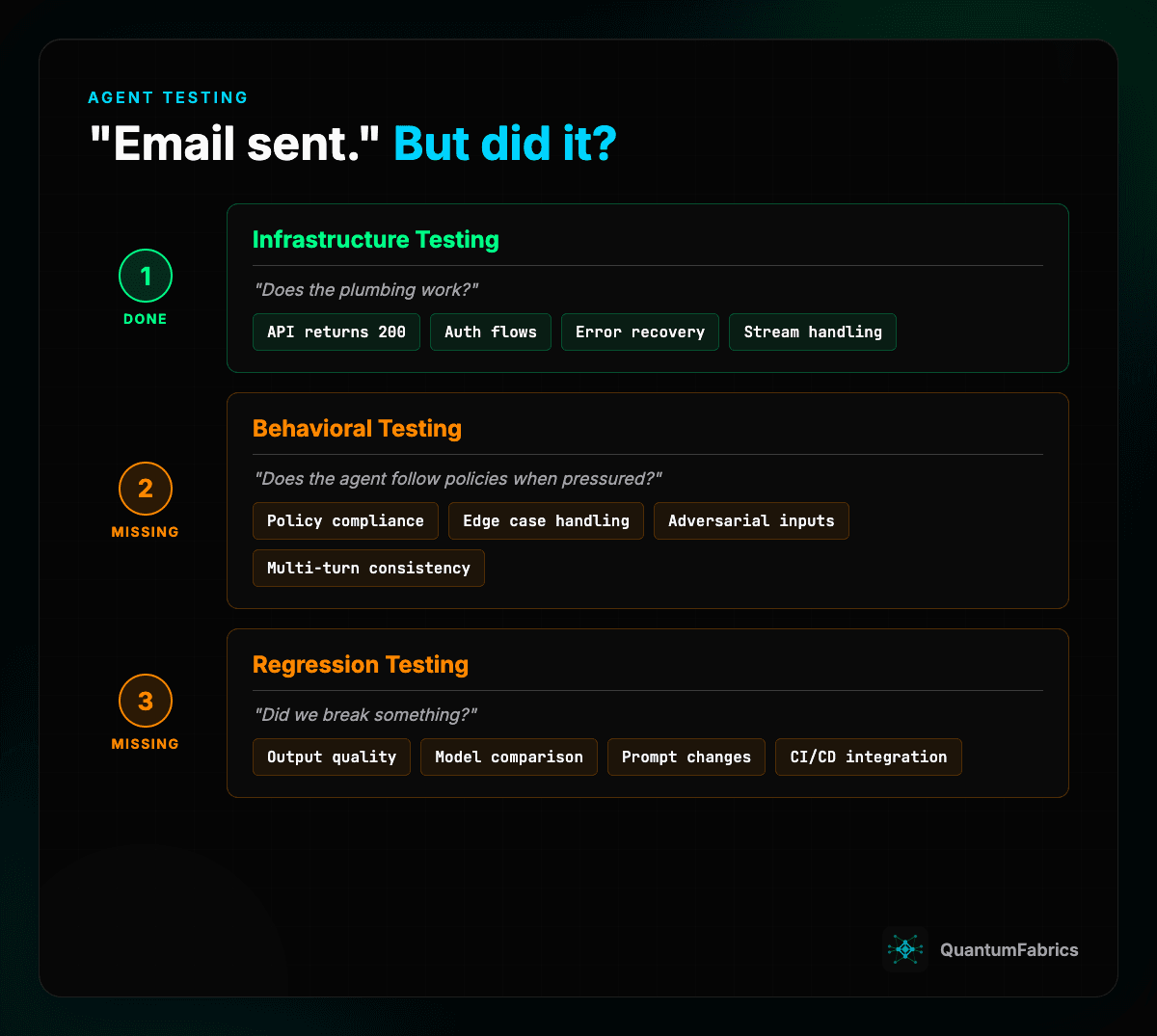
1. Infrastructure Testing (Unit/E2E)
Tools: Vitest, Playwright, Jest
Tests: Does the plumbing work?
- API endpoints return correctly
- Authentication flows succeed
- Error recovery triggers appropriately
- Stream handling works
This is table stakes. Every team should have this.
2. Behavioral Testing (Policy Compliance)
Tools: IntellAgent, custom scenario generators
Tests: Does the agent follow the rules when pressured?
IntellAgent uses a three-stage approach:
- Policy Graph Modeling: Nodes = policies, edges = co-occurrence likelihood
- Synthetic Scenario Generation: Auto-generate edge cases based on complexity scores
- User Simulation: Simulate realistic multi-turn conversations
- Fine-Grained Analysis: Detect policy violations automatically
The results: 0.98 Pearson correlation with manually curated benchmarks on airline domain.
# Example IntellAgent config
policies:
- name: "email_domain_restriction"
rule: "Only send emails to @company.com domains"
complexity: 0.7
- name: "no_direct_recommendations"
rule: "Never recommend specific candidates"
complexity: 0.5
3. Regression Testing (Did We Break Something?)
Tools: Promptfoo, LangSmith, custom evaluators
Tests: Did changes introduce regressions?
Promptfoo approach:
- Declarative YAML configs
- Batch testing against scenarios
- CI/CD integration
- Red teaming for security
# promptfoo config
prompts:
- "You are a recruiting assistant..."
tests:
- vars:
query: "Email all candidates about the opening"
assert:
- type: not-contains
value: "@external.com"
LangSmith approach:
- Offline evals on curated datasets
- Online evals on production traffic
- Human annotation queues
- Drift detection
Platform-Specific Options
AWS: Bedrock Model Evaluation
- Automatic evaluation against built-in metrics
- Custom evaluation jobs with your datasets
- Human evaluation via SageMaker Ground Truth
GCP: Vertex AI Model Evaluation
- Pre-built metrics for conversational AI
- Custom metrics via Cloud Functions
- BigQuery integration for analysis
Azure: AI Foundry
- Model benchmarking on public/custom datasets
- A/B experiments for AI applications
- Integrated with Azure deployment infrastructure
Open Source Stack
Combine tools for full coverage:
- Promptfoo - CI/CD regression testing
- IntellAgent - Behavioral/policy compliance
- Custom metrics - Resilience tracking
- OpenTelemetry - Trace-based observability
A/B Testing for Agents
Traditional A/B tests treat every result equally. Agent performance varies by conversation type, user, and scenario.
Parloa's hierarchical Bayesian approach:
- Combines binary metrics + LLM-judge scores
- Accounts for variation across scenarios
- Partial pooling captures both group and individual differences
Key infrastructure requirements:
- Traffic routing with user consistency
- Model isolation (separate containers)
- Unified logging across all variants
- Sample size calculation before testing
Key Takeaways
- Testing deterministic code asks "does it work?"
- Testing agents asks "does it follow the rules when pressured?"
- You need infrastructure testing, behavioral testing, AND regression testing
- IntellAgent handles behavioral testing with synthetic scenarios
- Promptfoo handles regression testing in CI/CD
- Most teams only do infrastructure testing - that's not enough
Learn More
Want to learn how to build production AI systems? I cover this and more in my Enterprise AI course.
Sources:
Sources
- IntellAgent Paper - Multi-agent evaluation framework, 0.98 correlation
- Promptfoo - CLI-first evaluation with red teaming
- LangSmith Evaluation - Managed evaluation platform
- Parloa A/B Testing - Hierarchical Bayesian approach
First Comment (for publish script)
Here's the course link: https://maven.com/p/ab66a8/enterprise-ai-blueprint-pilot-to-production