Multi-Tier Memory: What Agents Learn from Human Cognition
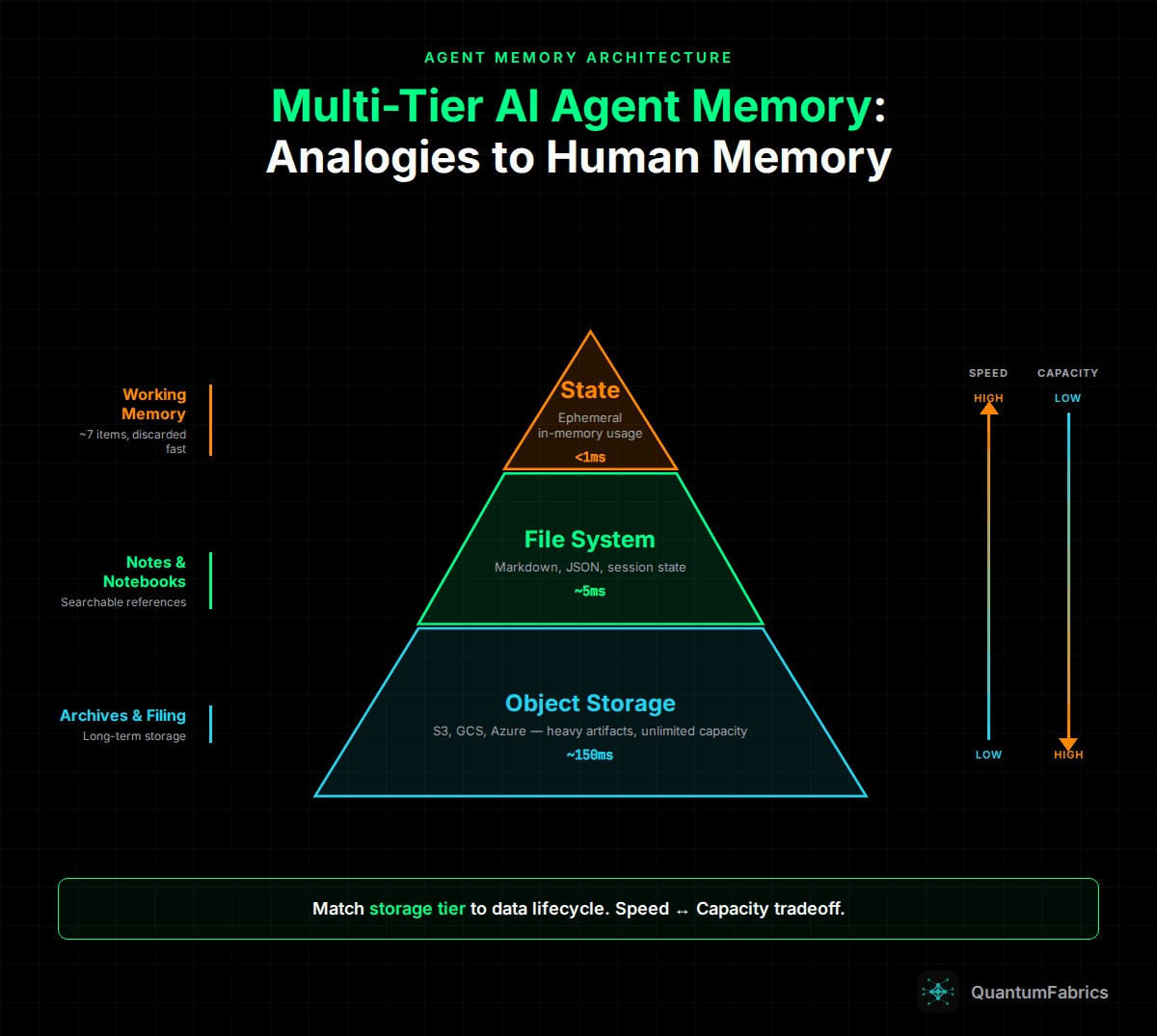
Production AI agents need memory architectures that mirror human cognition - working memory, notebooks, and archives mapped to ephemeral states, file systems, and object storage.
Multi-Tier Memory: What Agents Learn from Human Cognition
Humans don't try to hold everything in working memory. We naturally evolved a tiered cognitive system: immediate recall for active tasks, notes and notebooks for medium-term reference, filing cabinets for long-term storage.
Production AI agents need the same architecture.
The Human Memory Model
Before diving into implementation, consider how you actually work:
Working Memory: You can hold about 7 items in active recall. When solving a problem, you focus on immediate inputs and discard details once processed.
External Notes: For anything beyond immediate tasks, you write it down. Meeting notes, to-do lists, project summaries. Quick to create, easy to search, referenced when needed.
Archives: Documents you might need someday. Filed away, indexed, retrieved occasionally. You don't keep tax records from 2019 in your head - you know where to find them.
Agents face the same constraints. Context windows are working memory. Treating them as unlimited storage is like trying to memorize every document you've ever read.
Tier 1: Short-Term Memory (Ephemeral State)
The ephemeral state is RAM. Fast access, limited capacity, constantly recycled.
Characteristics:
- Token limits (32k-200k depending on model)
- Performance degrades as it fills
- Cleared between sessions (unless explicitly persisted)
- Expensive - every token costs inference time and money
What belongs here:
- Current user request
- Immediate context needed for response
- Active tool call results
- Recent conversation turns (compressed)
What doesn't belong:
- Full file contents (unless actively processing)
- Complete conversation history
- Reference documentation
- Previously generated artifacts
The Rule: If you're not actively reasoning about it right now, it shouldn't be in context.
Tier 2: Medium-Term Memory (File System)
Structured, searchable storage that persists across sessions. This is your agent's notebook.
Implementation Options:
- Markdown files in a workspace directory
- JSON state files with structured data
- SQLite for relational queries
- Vector stores for semantic search
Characteristics:
- Millisecond access times
- Easy to grep and search
- Survives session boundaries
- Human-readable (important for debugging)
What belongs here:
- Conversation summaries
- Task state and progress
- User preferences learned over time
- Extracted entities and facts
- Session metadata
Pattern: The Checkpoint File
# Session Summary - 2026-02-05
## User Context
- Working on: quarterly report
- Preferences: formal tone, bullet points
- Timezone: PST
## Completed Tasks
- [x] Drafted executive summary
- [x] Generated revenue charts
## Pending
- [ ] Competitor analysis section
- [ ] Final review
## Key Decisions
- Using FY25 data (confirmed by user)
- Charts in PNG format per brand guidelines
When a new session starts, load this summary into context instead of replaying the entire conversation. Hundreds of messages compressed to a few hundred tokens.
Tier 3: Long-Term Memory (Object Storage)
Durable storage for heavy artifacts. This is the filing cabinet.
Implementation Options:
- AWS S3
- GCP Cloud Storage
- Azure Object Storage
- MinIO (self-hosted)
Characteristics:
- Unlimited capacity
- Durable (11 9's reliability)
- Slower access (network latency)
- Cost-effective for large files
What belongs here:
- Generated documents (PDFs, reports)
- Uploaded files from users
- Images and media
- Conversation archives
- Audit logs
Pattern: Reference by Path
Don't inject blob content into context. Store a reference:
{
"artifact_type": "quarterly_report",
"storage_path": "s3://agent-artifacts/reports/q4-2025.pdf",
"created_at": "2026-02-05T10:30:00Z",
"summary": "Q4 2025 financial report, 24 pages, includes revenue charts",
"metadata": {
"pages": 24,
"size_bytes": 2847291
}
}
The agent knows the artifact exists and what it contains. If it needs the actual content, it fetches from storage. Most requests never need the full file - just confirmation it was created.
The Memory Flow
Here's how the tiers work together in practice:
Request arrives:
- Load relevant session summary from file system (Tier 2)
- Check if any blob references are needed (Tier 3)
- Process request in ephemeral state (Tier 1)
During processing:
- Keep context focused on immediate task
- For large file processing, stream chunks rather than loading entirely
- Write intermediate results to file system
After response:
- Update session summary in file system
- Store any generated artifacts to object storage
- Clear working context of processed information
Session end:
- Generate final session summary
- Archive full conversation to object storage
- Clean up temporary files
Common Anti-Patterns
The Context Hoarder Keeping entire conversation history in context "just in case." After 50 messages, the model can't find relevant information in the noise.
The Eager Loader Injecting full file contents when the agent only needs to confirm receipt. A 50-page PDF shouldn't consume context until someone asks about page 37.
The Stateless Agent Treating every request as independent. Users repeat themselves because the agent forgot preferences established in previous sessions.
The Single-Tier System Using only ephemeral state, or only database storage. Missing the middle tier means either context overflow or slow retrieval for common operations.
Implementation Checklist
Tier 1 (Ephemeral State):
- Set explicit token budgets per request type
- Implement summarization for long conversations
- Use streaming for large file processing
- Monitor context usage in production
Tier 2 (File System):
- Define session summary schema
- Implement checkpoint save/restore
- Add search capability (grep, semantic, or both)
- Set retention policies
Tier 3 (Object Storage):
- Choose storage provider (S3, GCS, Azure)
- Implement reference-by-path pattern
- Add metadata indexing
- Configure lifecycle rules for cleanup
The Payoff
Proper memory architecture is the difference between:
- Demos that work with 5-minute conversations
- Production systems that handle 5-hour sessions with hundreds of files
Humans figured out cognitive offloading millennia ago. Writing, filing systems, and libraries are external memory. Your agent needs the same infrastructure.
Context windows are working memory. Treat them like RAM - valuable, limited, and constantly recycled. Build the filing system around them.
Further Reading: